Contents
Heredity is the passing on of features from parents to offspring by means of genes. Organisms inherit genes from their parents.
GENES
Genes are carried on DNA. A gene is a section of DNA that causes the production of protein which is the production of the animal or plant part. (Living material is built up by proteins.)
Many of the genes produced are enzymes. Enzymes were discussed in the enzymes web page which can be found on the homepage.
GENE EXPRESSION
Gene expression is the process by which inheritable information from a gene is made into protein or RNA.
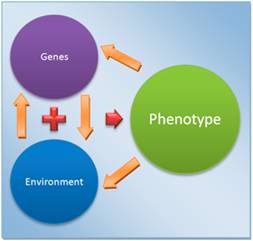
In plain language gene expression is how a gene works. Gene expression functions in the environment of the living organism. If the environmental factors are not correct then the characteristic produced by the gene may not be expressed. The way an organism physically looks is called its phenotype. The phenotype is determined by genes but is influenced by toe organisms’ environment.
DNA, GENES, AND CHROMOSOMES
DNA (deoxyribose nucleic acid) molecules are large and complex. They carry the genetic code that determines the characteristics of a living thing.
Except for identical twins, each person’s DNA is unique. This is why people can be identified using DNA fingerprinting. DNA can be cut up and separated, forming a sort of “bar code” that is different from one person to the next.
A gene is a short section of DNA. Each one codes for a specific protein by specifying the order in which amino acids must be joined together.
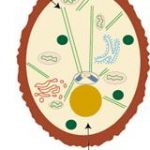
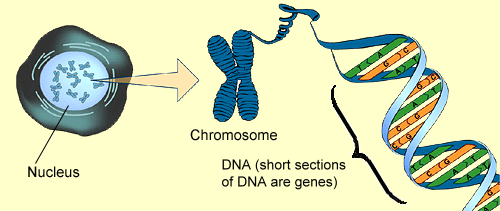
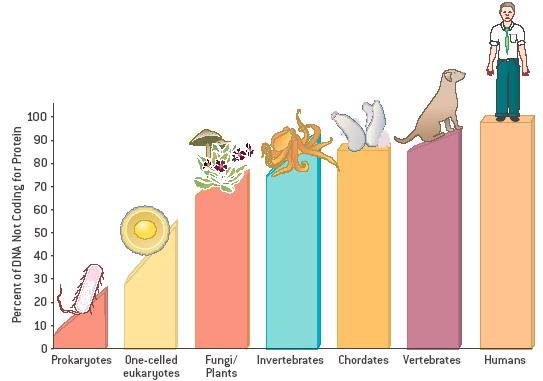
The cell’s nucleus contains chromosomes. Chromosomes are made up of protein and DNA. The protein holds the DNA in a tightly packed shape place in the nucleus. The DNA is very long and would not fit into the nucleus if this didn’t occur. Genes are located on the DNA. They are placed in line. Some genes are close together and others are far apart from other genes. There are many parts of chromosome that contain no genes. In fact, about 97% of a chromosome of a human has no genes. These parts of the chromosomes between the 2 genes are called non-coding protein sequences (sometimes called “junk DNA”).
The diagram shows the relationship between the cell, its nucleus, chromosomes in the nucleus and genes.
The regions with no genes are the non-coding sequences:

PERCENTAGE OF NON-CODING SEQUENCES IN VARIOUS SPECIES:
THE STRUCTURE OF DNA
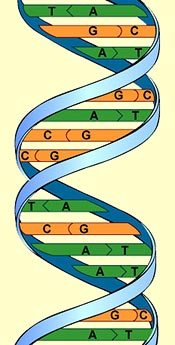
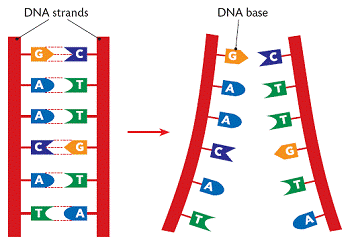
DNA is composed of 4 bases. These bases go together in pairs. The 4 bases are known by the first letter of their name:
A = Adenine
T = Thymine
G = Guanine
C = Cytosine
Each base can only join with one other base.
A can only join with T
![]()
G can only join with C

The way that one type of base links to another type of base is known as complementary base pairing.
It is the precise number and arrangement of these base pairs along the DNA that forms the organism’s genetic code.
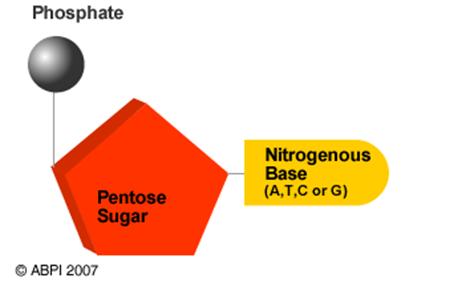
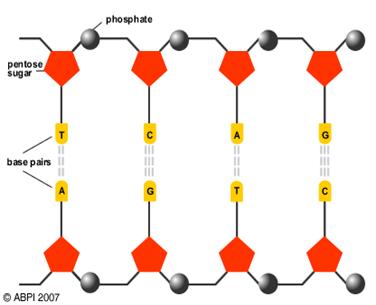
As can be seen above, each pair of bases are held on the side strands (some times called the “backbones”) of the DNA. These side strands are made up of a pentose sugar (a 5-carbon sugar) and a phosphate group, The entire unit is then made of three molecules: a pentose sugar (a 5-carbon sugar) and a phosphate group a nitrogenous base. This smallest unit of DNA is called a nucleotide.
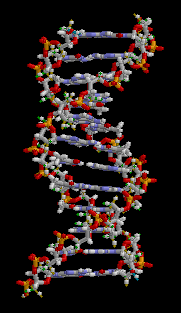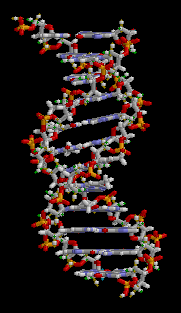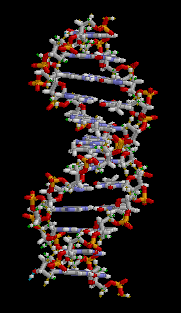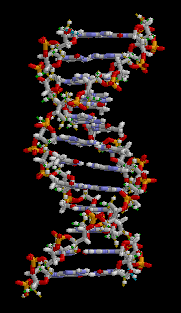
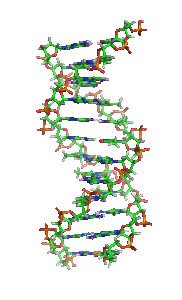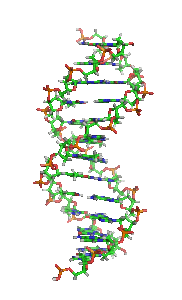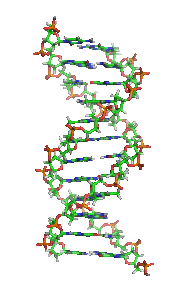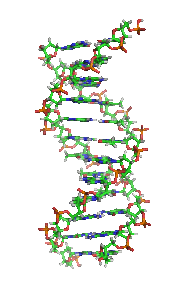
THE DOUBLE HELIX
DNA IS FOUND IN CELLS IN A TWISTED FORM CALLED A DOUBLE HELIX:
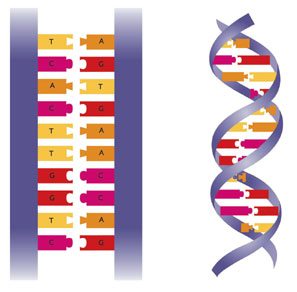
THE GENETIC CODE
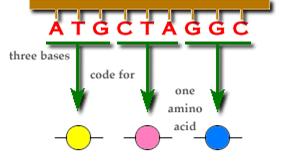
Proteins are made up of amino acids. Amino acids are made up of a set of 3 nucleotides called triplets or codons. There are 20 amino acids that are used to form a variety of proteins. There are many combinations of amino acids that make up the proteins that are an organism’s body.
1 amino acid:
Here we see the formation of 3 amino acids:
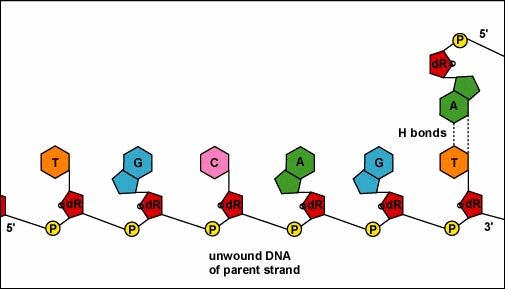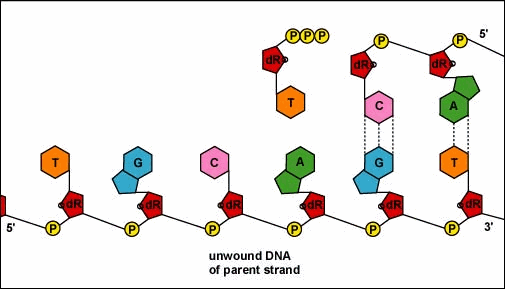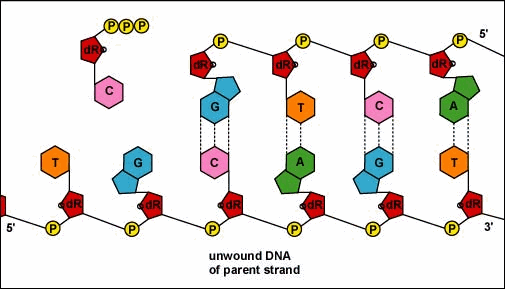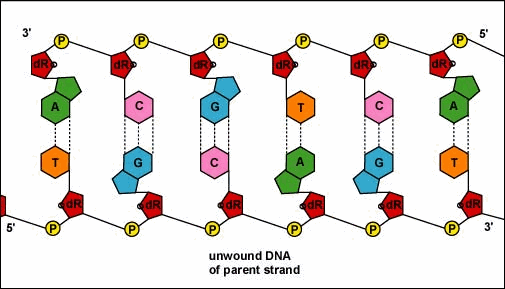
DNA REPLICATION
As we learned in the mitosis web page when a cell divides the DNA must produce an exact copy of itself. This replication takes place during interphase of mitosis. The process can be listed as follows:
1. Nucleotides are made in huge quantity in the cytoplasm.
2. An enzyme unzips the two complementary strands of DNA.
3. New complementary nucleotides link to the exposed bases on the separated strands.
REMEMBER:
A can only join with T
G can only join with C
4. A new complementary strand is built along each ‘old’ strand.
5. Two DNAs, identical to the original and each other, are now present.
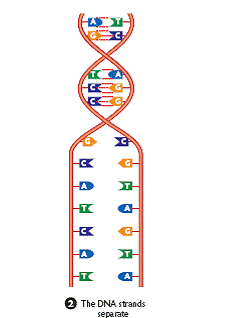
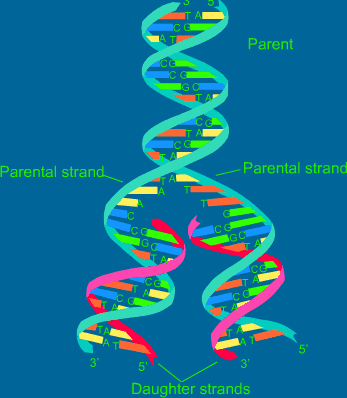
As a result of DNA replication the 2 cells formed by mitosis are exact duplicates.
DNA PROFILING
DNA profiling is popularly known as DNA fingerprinting. It produces a unique pattern from an individual’s DNA which can then be used to distinguish that individual form another. Extremely variable regions of non-coding DNA are used.
Genetically different individuals produce different profiles. The closer the genetic relationship between individuals the more similar their profiles.
METHOD OF DNA PROFILING
1. The DNA is released from a cell: The cells of an uncontaminated biological sample (blood, semen, hair root, cheek cell) are broken open and the DNA is released and separated. If the amount of DNA is small the DNA can be amplified (increased) by a process called polymerase chain reaction (PCA).
2. Digestion: Special enzymes are used to cut the DNA at specific points and produce a set of fragments of varying lengths. These enzymes are called restriction enzymes. The DNA sections that are cut are called restriction fragments. Certain enzymes will cut the DNA at specific bases (T, G, A, and C). Each restrictive fragment will be specific for that particular person. The bases as well as the distance between the bases (non-coding DNA) are characteristics of that individual organism (person).
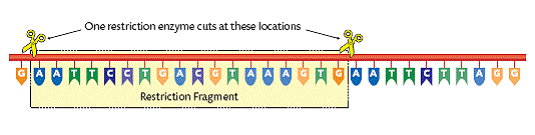
3. Separation: The fragment mixture is placed in a block of gel and separated by gel electrophoresis on the basis of size. The fragments are exposed to an electrical charge. This causes the fragments to move. The smaller the fragment the further it travels. The bands of small fragments are separated from the bands of the large fragments. After other treatments, a photographic copy of the pattern of DNA is compiled. Using certain methods the positions of the DNA fragments on X-ray film appear as dark bands. The positions of these bands are the genetic profile of the individual and the more numerous the bands the more reliable the ‘fingerprint’. The bands are produced and vary in thickness depending on how many DNA fragments are present in a certain length of DNA. Remember that there are many parts of the chromosomes that don’t contain coding DNA.
4. Pattern comparison: The DNA fingerprint can be used to be compared to other DNA fingerprints. The pattern is unique to an individual. In this way comparisons of known DNA to unknown DNA can be made to determine if the unknown DNA can be identified.
Applications of DNA Profiling
Crime: Forensic medicine uses medical evidence in legal disputes. DNA profiling is used in forensic medicine. Material such as hair, semen, blood, and saliva which is left at a crime scene can be compared with possible suspects to find out if the suspect was at the crime scene.

Medical: DNA profiles can be used to determine the parents of a child.
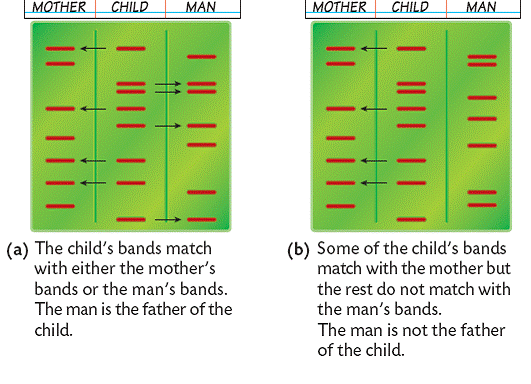
GENETIC SCREENING
Genetic Screening is used to find out if the parents of a child or the child itself (through removal of cells from the foetus) carry defective genes that could develop into health problems. Although the parent may not have the disorder he/she could be a carrier for the condition. With genetic screening, prospective parents can determine if there is a possibility that their future children could have the health problem.
RNA (RIBONUCLEIC ACID)
RNA, like DNA, is made up of 2 of 4 bases. The bases of RNA are as follows:
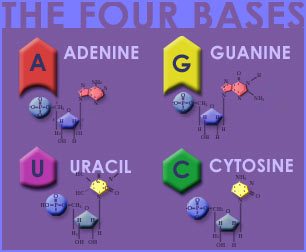
As you can see, Uracil takes the place of Thymine in RNA. So, the bases in RNA are:
A = Adenine
U = Uracil
G = Guanine
C = Cytosine
A = Adenine is complementary (combines with) U = Uracil
G = Guanine is complementary with C = Cytosine
Unlike DNA, RNA is single stranded. The RNA produced is complementary to the DNA which produced it. Also, RNA can move out into the cytoplasm while DNA remains in the nucleus.
DNA RNA
G C
G C
A U (There is no T in RNA so U is the complement of A)
A U
T A
C G
PROTEIN SYNTHESIS
As stated previously, genes are responsible for the formation of protein. The protein could be new body cells or enzymes.
The base sequence of the DNA determines the properties of the new protein produced.
Each 3 segment group (triplet/codon) produces an amino acid. The amino acids form protein.
STAGES OF PROTEIN SYNTHESIS
1. Initiation: Just like in DNA Replication the DNA strands separate into 2 chains. (occurs in the nucleus)
2. Transcription: RNA complementary bases attach to the bases on one side of the strand. When this happens the code has been transcribed. This RNA strand is called messenger RNA (mRNA).
![]()
3. The mRNA detaches from the DNA strand and moves out of the nucleus and into the cytoplasm.
4. The mRNA enters and passes through a ribosome. The amino acids (codons/triplets) form proteins. We say that the mRNA has been translated at the ribosome to form protein.
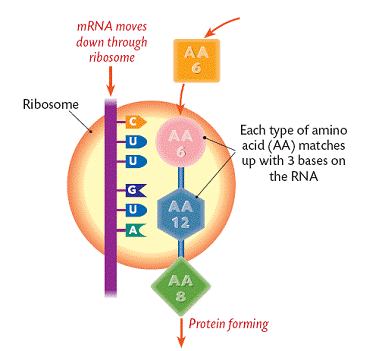
Each codon/triplet forms a particular amino acid. As seen above, CUU forms AA6 and GUA forms AA12.
Many of these amino acids (up to 20 depending on the protein formed) join to form the new protein.